
Identifying and addressing common errors in AI systems and strategies for continuous improvement
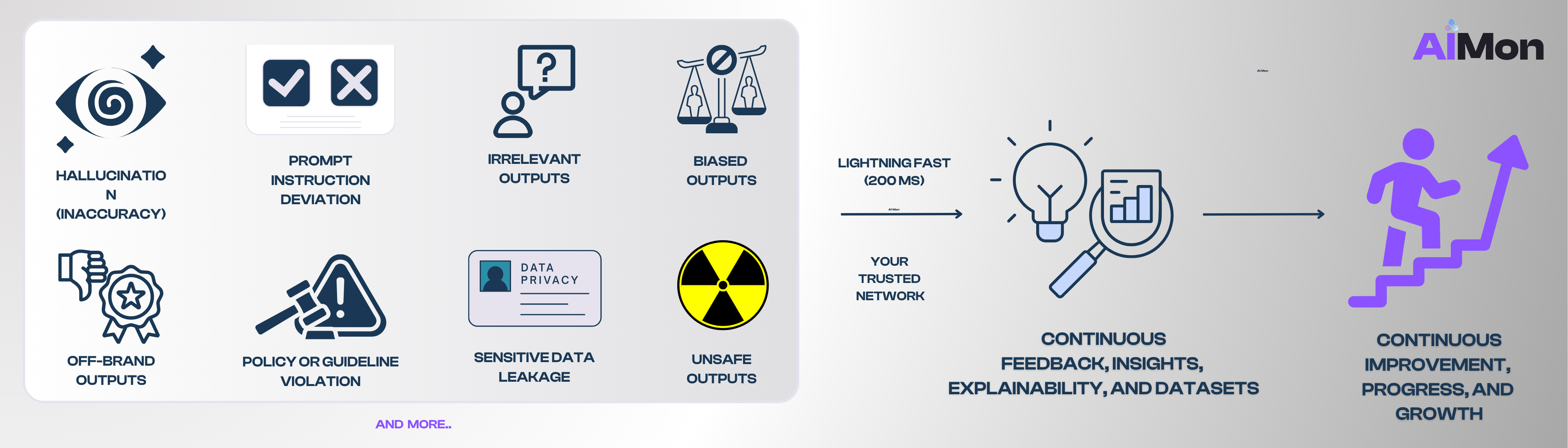
AI failures do not just happen in development. They might happen quietly in production. A single incorrect answer, biased response, or hallucinated output can erode trust faster than any model benchmark can repair.
Yet far too many teams operate without continuous monitoring, meaningful feedback loops, and scalable ways to evaluate real-world model behavior.
At AIMon, we believe this is not just a technical oversight. It is a structural flaw. And it must be corrected with urgency. The challenges are clear. So are the solutions.

Many teams evaluate AI during development and assume it will behave as expected. But AI models are probabilistic. Data they use evolves. User queries come in many forms. Without ongoing monitoring, deployed systems operate blindly in a dynamic environment.
When errors happen, many organizations lack the infrastructure to trace what failed, understand why it failed, or determine how to fix it. Manual reviews are slow and incomplete. Metric tracking is fragmented or absent. Business-critical evaluation criteria are often ignored because they are hard to define or implement.
This is more than a tooling gap. It is a failure to align engineering, product, compliance, and leadership on what reliable AI looks like in the real world.
Agentic AI projects hit significant roadblocks due to inaccuracy, instruction deviation, safety, and compliance problems magnified by each agentic step. Agentic and autonomous AI systems cascade failures, increase cost, and introduce new risks around loss of control, decision accountability, and potential “wrong” or “rogue” actions (tool calls).
The consequences of unmonitored AI behavior could be immediate and damaging.
Leaders face increased scrutiny. Failures in AI output result in accountability for compliance violations, public missteps, and customer dissatisfaction. The absence of transparency and safeguards creates institutional risk.
When agentic AI apps fail in production, companies might face business disruption, reputational damage, and increased legal or compliance risk. For executive leaders, this means lost credibility, stalled innovation, tougher oversight, and greater challenges scaling AI across the enterprise.
Engineering teams become reactive and overwhelmed. Without continuous visibility, engineers are stuck troubleshooting issues long after damage has occurred. Firefighting replaces innovation. Model development slows to a crawl.
AI projects stagnate or collapse. Without structured improvement pathways, AI projects struggle to reach production. Even when deployed, they remain underutilized because stakeholders do not trust their reliability or safety.
ROI declines and confidence erodes. Lack of measurable success leads to reduced buy-in, tighter budgets, and missed opportunities for scaling AI across the enterprise.
To operate AI successfully in production, companies must move from static evaluation to dynamic oversight. This requires several deliberate shifts:
Monitor AI systems in production using real-world metrics. Evaluation must be ongoing. This includes tracking accuracy, safety, compliance, and instruction adherence on live traffic or outputs.
Establish scalable feedback loops. Real-world feedback must flow directly into model optimization, fine-tuning, and retraining pipelines. This iterative process turns every deployment into a learning system that can rapidly cut down the time needed to ship AI projects.
Empower domain experts to define quality standards. Success should not be defined solely by engineers. Legal, financial, healthcare, and other domain teams must contribute their own definitions of correctness, safety, and compliance.
Automate identification of failure modes. Manual review is not sustainable. Intelligent triage systems must surface the right outputs for review and enable targeted human input.
Define clear boundaries for agentic AI systems. AIMon helps you define clear boundaries for each agent’s expected behavior to enforce the bounds they operate in. AIMon empowers Engineering teams to improve accuracy of Agentic apps in real-time by implementing the “reflection” pattern at each agent to keep them in check for various metrics like Accuracy, or custom business policies, or even tool calls.
AIMon provides the infrastructure, intelligence, and velocity needed to solve these challenges with clarity and confidence.
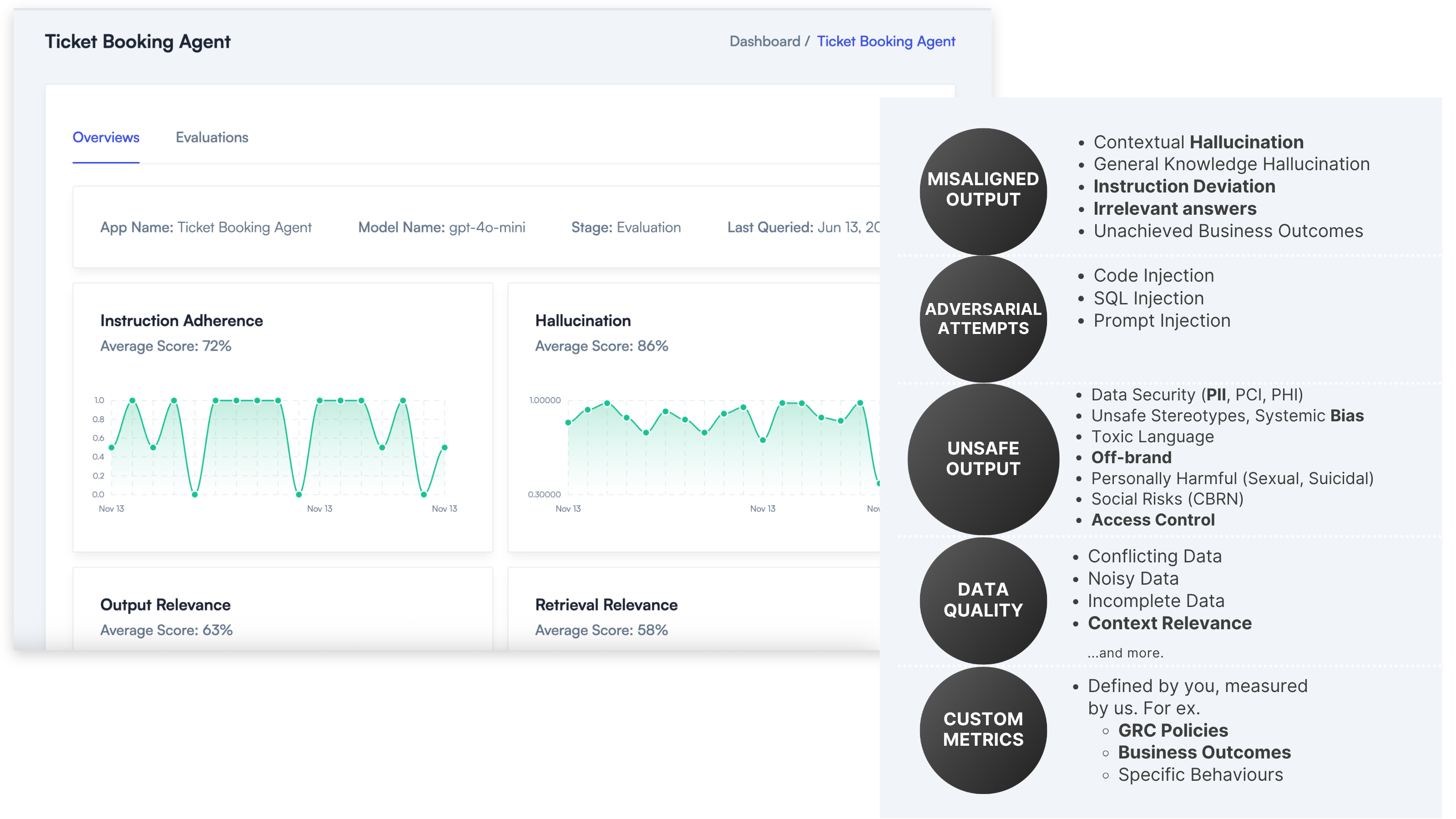
Our real-time guardrails work in a latency budget of 300ms depending on underlying hardware. Our models are strikingly faster than any competition and don’t require you (on-prem) or us (hosted) to deploy the heaviest GPUs. They help validate outputs in real time and provide you the insight to take the desired next step, whether it is to block the call, escalate to a human expert, or to get a better response from your AI model!
This is especially beneficial for Agentic systems where you gain adherence, relevance, safety, and much more without sacrificing performance.
From there, you can enforce thresholds or take action automatically when risky behavior is detected.
One line of code activates real-time evaluations of your AI stack using over 20 production-ready metrics across safety, adversarial robustness, factual accuracy, and data quality. These evaluations cover LLMs, RAG pipelines, and agent-based systems.
Domain experts can write plain-English expectations which AIMon automatically transforms into executable evaluation metrics in minutes. Experts can be Product Managers, Security Experts, Governance leads, Lawyers, and other people who work closely with you.
This makes it possible to encode domain-specific standards for correctness, regulatory adherence, and brand safety without complex engineering.
AIMon delivers tangible outcomes across the entire enterprise AI lifecycle.
Customer trust increases through consistently monitored and validated AI behavior. Risk is reduced by catching and correcting issues before they reach users. Audit readiness becomes real as every decision can be explained, every outcome traced. Innovation accelerates because teams have clarity and control, not chaos. Time to value shortens as model feedback becomes model progress.
AI is no longer theoretical. It is operational. And operational systems require visibility, control, and feedback. You cannot manage what you do not measure. You cannot improve what you do not monitor. And you cannot lead with AI unless you can trust it.
At AIMon, we are building the foundations that enterprise AI requires to function at scale. These are not optional features. They are the backbone of any serious AI deployment strategy.
If you are ready to move beyond experimentation into performance, beyond hope into confidence, beyond static evaluation into continuous improvement, we are ready to work with you.
Let us help you lead with data that is seen, models that are safe, and AI that earns its place in your business.
Backed by Bessemer Venture Partners, Tidal Ventures, and other notable angel investors, AIMon is the one platform enterprises need to drive success with AI. We help you build, deploy, and use AI applications with trust and confidence, serving customers including Fortune 200 companies.
Our benchmark-leading ML models support over 20 metrics out of the box and let you build custom metrics using plain English guidelines. With coverage spanning output quality, adversarial robustness, safety, data quality, and business-specific custom metrics, you can apply any metric as a low-latency guardrail, for continuous monitoring, or in offline evaluations.
Finally, we offer tools to help you iteratively improve your AI, including capabilities for real-world evaluation and benchmarking dataset creation, fine-tuning, and reranking.